AI agents are moving from answering questions to operating in worlds. A real agent should not only follow instructions or click buttons. It should understand how the world changes after each action. It should remember past experience, predict future states, explain failures, and choose actions that cause progress. This is the goal of World Agent: an agent that acts through an internal causal model of its environment. To build it, we need a causal brain.
Why Agents Need Causality
Today’s agents are powerful but fragile. They can browse websites, use tools, and complete tasks, but they often fail when the environment changes. A button moves. A page behaves differently. A previous action creates an unexpected result. The agent may know what action usually comes next, but not why that action works. A world agent needs to understand the chain:
action → state change → observation → next action
For example, in a GUI task, the agent should know that changing a date can affect price, availability, and later payment options. If the task fails, it should trace the failure back to the specific earlier action that caused it. This is the difference between a reactive agent and a causal agent.
Memory: Learning from the Past
The first part of the causal brain is memory. An agent cannot start from zero every time. It needs to accumulate experience and reuse it. Our work on Self-evolving Scalable Memory explores this direction. In video generation, plug-and-play memory helps models reuse visual and physical patterns from reference videos[1]. In GUI agents, structured memory stores tasks, states, actions, and trajectories as connected knowledge[2,3]. Continuous memory further allows agents to preserve detailed GUI experience, including layouts, widgets, and interaction histories. The key idea is: Memory should not only store what happened. It should organize experience into reusable knowledge. But memory alone only tells the agent the past. The agent also needs to imagine the future.
World Model: Simulating the Future
A world model gives the agent imagination. In C-World[4], we study how to create scalable environments for computer-use agents. Instead of relying only on fixed benchmarks, C-World can generate diverse tasks, tools, interfaces, transitions, and rewards. This gives agents more worlds to learn from. In PAN[5], we move toward a general world model that can simulate future states from past observations and natural-language actions. This allows the agent to ask: what will happen if I take this action? For agents, the world model should not only generate realistic futures. It should generate action-valid futures. The future must respect the consequences of the agent’s actions. This is where world modeling meets causality.
Modularity: Controlling the Right Ability
A world agent needs many abilities: memory retrieval, visual grounding, planning, simulation, long reasoning, tool use, and recovery. These abilities should be modular and controllable. Our work on Ability Transfer and Recovery via Modularized Parameters Localization[6] shows that abilities can be localized in small parts of model parameters, making it possible to transfer, recover, and merge abilities with less interference. Our work on Activation Control for Long Chain-of-thought Ability[7] shows that reasoning behavior can be activated through internal model control. The agent does not need to always think longer. It should reason deeply only when the situation requires it. A world agent should know when to retrieve memory, when to simulate, when to reason, and when to act.
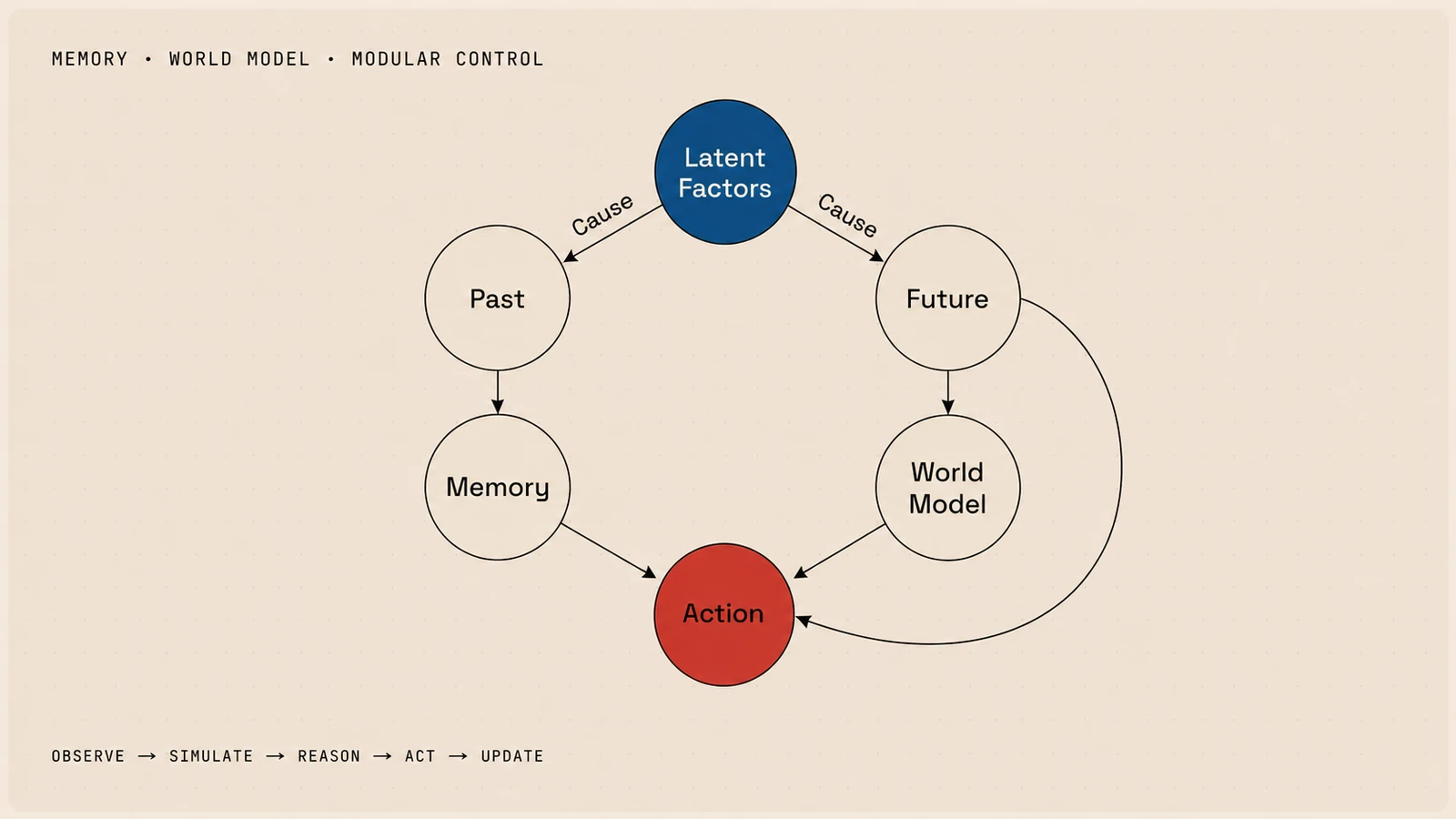
The Causal Brain
Memory, world models, and modular abilities become much stronger when connected by causality. A causal brain helps the agent answer four questions: What happened? Memory records past actions and outcomes. Why did it happen? Causal reasoning identifies which action caused which state change. What will happen next? The world model simulates possible futures. What should I do now? Modular control activates the right ability for the current situation. Together, they form the loop of World Agent:
observe → retrieve memory → simulate futures → reason about causes → act → update memory
This loop allows the agent to learn from experience, predict consequences, recover from mistakes, and improve over time.
Toward World Agent
The next generation of agents will not be judged only by whether they can complete a task once. They will be judged by whether they can understand the environment, adapt to changes, explain failures, and improve through interaction. Memory gives the agent experience. World models give the agent imagination. Modularity gives the agent controllable abilities. Causality gives the agent understanding. Our previous works on scalable memory, world simulation, and ability control are three foundations for this direction. The next step is to integrate them into one system: a World Agent that learns from the past, simulates the future, and acts through causal understanding. That is the core idea behind Building the Causal Brain of World Agent.
References
- Song, S., Xu, Z., Zhang, Z., Zhou, K., Guo, J., Qin, L., & Huang, B. Learning Plug-and-play Memory for Guiding Video Diffusion Models. arXiv preprint arXiv:2511.19229, 2025.
- Wu, W., Zhou, K., Yuan, R., Yu, V., Wang, S., Hu, Z., & Huang, B. Auto-scaling Continuous Memory for GUI Agent. arXiv preprint arXiv:2510.09038, 2025.
- Zhu, S., Wu, W., Zhou, K., Wang, S., & Huang, B. Hybrid Self-evolving Structured Memory for GUI Agents. arXiv preprint arXiv:2603.10291, 2026.
- Xi, Z., Liang, S., Liu, Q., Zhang, J., Peng, L., Nan, F., Nayim, M., Zhang, T., Mundada, R., Qin, L., Huang, B., & Zhou, K. C-World: A Computer Use Agent Environment Creator. arXiv preprint arXiv:2601.06328, 2026.
- PAN Team Institute of Foundation Models, Xiang, J., Gu, Y., Liu, Z., Feng, Z., Gao, Q., Hu, Y., Huang, B., Liu, G., Yang, Y., Zhou, K., et al. PAN: A World Model for General, Interactable, and Long-Horizon World Simulation. arXiv preprint arXiv:2511.09057, 2025.
- Jin, S., Zhou, K., Li, W., Wang, P., & Huang, B. Ability Transfer and Recovery via Modularized Parameters Localization. arXiv preprint arXiv:2601.09398, 2026.
- Zhao, Z., Liu, Q., Zhou, K., Liu, Z., Shao, Y., Hu, Z., & Huang, B. Activation Control for Efficiently Eliciting Long Chain-of-thought Ability of Language Models. arXiv preprint arXiv:2505.17697, 2025.