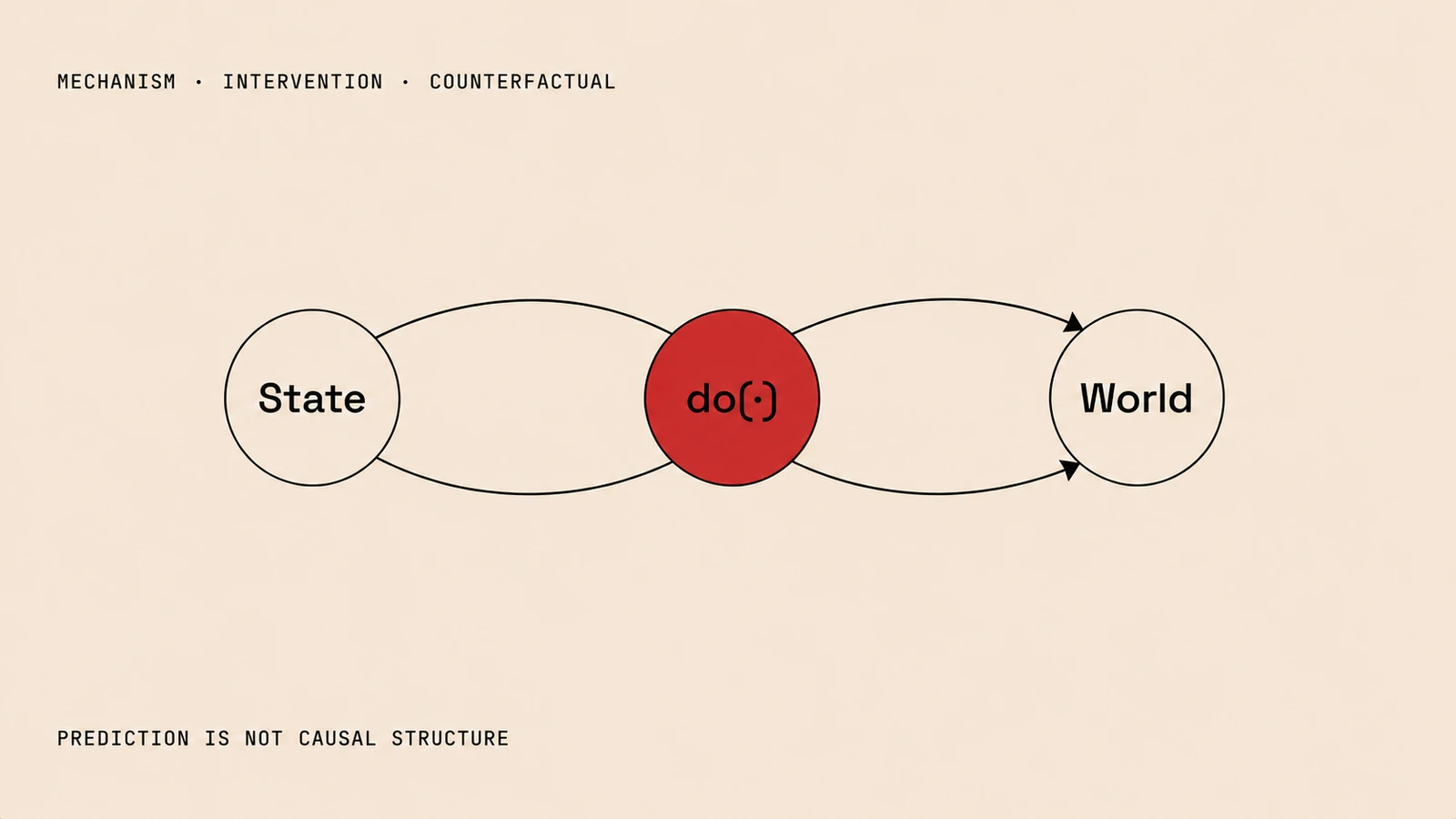
Modern machine learning has largely been built on statistical prediction. With enough data and model capacity, we can learn rich regularities in language, images, videos, molecules, biological measurements, and behavior. This has led to remarkable progress, but it does not remove a basic limitation: predictive structure is not necessarily causal structure.
A model may predict recovery without identifying the effect of treatment. It may predict disease progression from a biomarker that is only a downstream readout. It may imitate a robot trajectory without learning the physical mechanism that made the action succeed. In each case, the model can perform well under the observed distribution, but still fail under intervention, distribution shift, or deployment.
Causality studies what changes when we act on a system. It provides a language for mechanisms, interventions, and counterfactuals: not only what is likely to happen, but what would happen if something were changed [1–5]. This is becoming increasingly important as AI systems move from passive prediction to decision-making, where they recommend, plan, experiment, and act.
Causal Inference: Estimating the Effect of Intervention
Causal inference formalizes questions of the form: what would happen under an intervention?
The classical statistical formulation is the potential outcomes framework, associated with Neyman and Rubin, where causal effects are defined by comparing outcomes under alternative treatments [4,5]. Since only one potential outcome is observed for each unit, causal inference requires either experimental design or assumptions. Randomized controlled trials address this by making treatment assignment independent of potential outcomes, which is why they became central in medicine and social science.
A complementary formalism is Pearl’s structural causal model framework. In this view, variables are generated by structural assignments, and interventions are represented by modifying those assignments [1,2]. The distinction between conditioning on X=x and intervening with do(X=x) is fundamental: observing that a patient received treatment is not the same as assigning treatment; observing that a robot moved in a certain way is not the same as forcing that action.
Both traditions enforce the same discipline: specify the estimand, state the assumptions, and determine whether the target quantity is identifiable [1,2,4,5]. Causal inference does not remove assumptions. It makes them explicit.
For AI, this distinction matters because many deployed systems are evaluated by prediction accuracy even when the deployment question is interventional. A treatment recommendation, a robot action, a pricing policy, or an experimental design changes the system it is applied to.
Causal Discovery: Learning Structure from Data
Causal inference often assumes that the relevant causal structure is known. In scientific domains, this is rarely true. Biology, neuroscience, climate, economics, and robotics involve many interacting variables, latent factors, feedback loops, selection effects, measurement noise, and distribution shifts. Causal discovery asks whether aspects of causal structure can be recovered from data.
The classical field was shaped by work from Spirtes, Glymour, Scheines, Pearl, and others [1,6,7]. Constraint-based methods such as PC use conditional independence relations to recover equivalence classes of causal graphs [6,7]. Score-based approaches such as GES search over graph structures [8]. Functional causal model approaches, including LiNGAM and additive noise models, exploit asymmetries in the data-generating process to orient edges that are otherwise ambiguous [9,10]. Continuous optimization methods such as NOTEARS later reformulated DAG learning as a differentiable optimization problem [11].
Clark Glymour’s work helped establish graphical causal discovery as a computational and scientific program: what can be inferred from conditional independences, and under which assumptions [6,7]. Kun Zhang’s work expanded the field through functional causal models, kernel-based conditional independence testing, selection bias, nonstationarity, heterogeneity, and causal representation learning [10,12–15].
Biwei Huang’s work, often with Kun Zhang, Clark Glymour, Bernhard Schölkopf, and collaborators, has been especially important in moving causal discovery beyond idealized settings. A central theme of this work is to study causal identifiability under realistic violations of classical assumptions, including heterogeneity, nonstationarity, selection bias, partial observability, latent variables, and dynamical structure [14–25]. Rather than treating these phenomena only as nuisances, this line of work shows that changes across environments, time, and variable sets, together with structural constraints on latent-variable systems, can provide additional information for orienting causal relations and recovering structure that would be unidentifiable from a single stationary observational distribution [16–19,23–25].
This perspective is important because real data are rarely clean. In biology, two genes may be correlated because one regulates the other, because both share a hidden regulator, or because the relation appears only under a particular cellular condition. In robotics, a successful pushing action may depend on contact point, force direction, friction, geometry, support, and hidden constraints. A model that learns only the observed association may fail when the physical or experimental conditions change.
The purpose of causal discovery is not to produce decorative graphs. It is to generate structured hypotheses about mechanisms that can be tested, revised, and eventually used for intervention.
Causality for Robust and Transferable Learning
Causal machine learning begins from a practical failure mode of standard ML: strong in-distribution performance does not imply robustness under distribution shift. A classifier may learn that snow predicts wolves. A medical model may learn hospital-specific artifacts rather than disease mechanisms. A robot policy may learn visual regularities from demonstrations rather than contact, friction, force, and geometry.
Causal ML asks what structure should remain stable across environments. This motivation appears in invariant prediction, domain adaptation, domain generalization, invariant risk minimization, and mechanism-based transfer [26–31]. The underlying intuition, developed in part through work by Schölkopf, Zhang, Peters, Bühlmann, and others, is that causal mechanisms often provide more reusable structure than surface correlations [26–30].
Bernhard Schölkopf’s work is central to this view. The principle of independent causal mechanisms suggests that a data-generating process can often be decomposed into modular mechanisms, and that changes in one mechanism need not imply changes in all others [26,29,30]. This idea has influenced causal representation learning, transfer learning, and out-of-distribution generalization.
Biwei Huang’s work connects this perspective to learning systems that must adapt across environments and tasks. This includes causal discovery from heterogeneous and nonstationary data, mechanism-based clustering, nonstationary forecasting with state-space models, action-sufficient state representations for control, transfer reinforcement learning, nonstationary RL, and causal world-model-based adaptation [16–18,31–38].
The shift is from using causality only as an analysis tool to using causal structure as a computational asset. If a model can identify which mechanisms are stable and which have changed, it can adapt more efficiently, transfer across domains, and avoid relying on shortcuts that fail under deployment.
Causal Representation Learning
A central difficulty in bringing causality to modern AI is that the causal variables are often not given.
Classical causal models usually assume variables such as treatment, outcome, confounder, mediator, or instrument are already defined. Modern AI often begins with pixels, videos, language, trajectories, sensor streams, or single-cell measurements. The variables that govern the system may be latent, abstract, or only partially observed.
Causal representation learning asks how to recover variables that support intervention, counterfactual reasoning, transfer, and reliable prediction under changes in context or task [29,30]. Distribution shift is one source of information for identifying such variables, but it is not the only one. Temporal structure, sparsity, modularity, weak supervision, interventions, and structural constraints can also provide useful signals. The goal is not simply to learn disentangled factors in the usual representation-learning sense, but to learn abstractions that correspond to mechanisms.
This is where several research lines meet: Schölkopf’s work on independent causal mechanisms and causal representation learning [26,29,30]; Zhang’s work on functional causal models and distributional changes [10,12–15]; Glymour’s work on graphical causal discovery [6,7]; and Huang’s work on generalized score functions, heterogeneous and nonstationary causal discovery, latent hierarchical structures, identifiable latent models, and partially observed systems [15–25].
For AI, this is a core problem. A foundation model cannot reason causally if its internal variables do not correspond to stable, intervenable structure.
Causality for Decision-Making and Control
Causality is unavoidable when an AI system acts.
In supervised learning, a model may only predict an outcome under the observed data distribution. In decision-making, however, the model’s output changes the system it is modeling. A treatment recommendation changes patient outcomes. A pricing policy changes user behavior. A robot action changes the physical state of the environment. In all of these cases, the relevant question is not only what is likely to happen, but what would happen under a chosen intervention.
Reinforcement learning and control make this connection especially explicit. An action is an intervention on the environment, and a policy changes the state distribution it will later observe. This makes causal structure directly relevant to exploration, planning, transfer, and safety.
A causal world model can help an agent reason about how actions affect latent states, which mechanisms are task-relevant, what would have happened under alternative actions, and how to adapt when the environment changes. This line connects to counterfactual data augmentation, action-sufficient representations, transfer RL, nonstationary RL, and identifiable factorized world models [32–38].
Biwei Huang’s work in this direction is notable because it links causal structure to practical learning problems in control: what state information is sufficient for action, what changes across environments, how to adapt without relearning everything, and how counterfactual or factorized world models can improve data efficiency and generalization [32–38].
The broader point is that causal structure is not only useful for explaining decisions after the fact. It can improve decision-making itself by guiding exploration, reducing sample complexity, supporting transfer, and enabling recovery when the environment behaves differently from expectation.
Causal World Models as Causal Foundation Models
A causal world model represents a system in terms of state, action, mechanism, and outcome. It is not merely a predictor of future observations, but a model of how future states change under intervention. In this sense, a causal world model is a natural foundation model for real-world intelligence: it should learn the variables, mechanisms, and dynamics that remain meaningful when a system is acted upon.
This distinguishes causal world models from several neighboring paradigms. Vision-language-action models can learn mappings from observations and instructions to actions, but action is often treated as an output rather than as an intervention. Video generation models can produce plausible future frames, but visual plausibility does not imply causal correctness. Geometry-centric models and 3D reconstruction provide spatial structure, but geometry alone does not encode force, contact, dynamics, or how an action changes the world.
The central challenge is therefore not only to scale prediction, but to scale mechanism learning. In natural language, much of the relevant structure has already been compressed by humans into symbols, concepts, entities, events, and relations. In video, robotics, biology, medicine, and scientific experiments, the causal variables are often not given. They must be extracted from high-dimensional observations such as pixels, trajectories, sensor streams, molecular measurements, time series, and experimental readouts.
A causal foundation model should support interventional and counterfactual reasoning across these domains. In Physical AI, it should infer latent physical variables such as mass, friction, contact, support, compliance, geometry, and constraints; simulate candidate actions; compare counterfactual outcomes; update beliefs after unexpected transitions; and recover when reality differs from expectation. In biology and scientific discovery, it should distinguish drivers from downstream markers, identify hidden mechanisms, predict how interventions propagate, and suggest experiments that separate competing explanations.
This requires more than passive pretraining on observational data. Temporal structure, interventions, heterogeneous environments, simulation, active experimentation, sparsity, modularity, and feedback from failed predictions can all provide signals for learning causal structure. Evaluation must also change: next-token, next-frame, or behavior-cloning accuracy is not sufficient to test whether a model understands what would happen under a new intervention or distribution shift.
The deeper question for foundation models is not only whether they can model the distribution of observations, but whether they can recover variables, mechanisms, hidden drivers, and intervention-relevant structure from the world itself. This is the role of causal world models: to provide the foundation for AI systems that can generalize under distribution shift, reason about interventions, and discover new knowledge beyond observed correlations.
Why Causality Matters Now
Causality matters now not because scaling has failed, but because scaling has clarified where the next difficulty lies. In natural language, much of the relevant information has already been compressed by humans into explicit symbols, concepts, entities, events, and relations. Large language models benefit from this abstraction because the data already contains a high-level representation of the world.
Many real-world domains are different. In video, robotics, biology, medicine, and scientific experiments, the relevant causal variables are often not given. They must be extracted from high-dimensional observations such as pixels, trajectories, sensor streams, molecular measurements, time series, and experimental readouts. Before a model can reason causally, it must learn what the right variables are, how they interact, which mechanisms are stable, and how interventions change the system.
When a model completes text, statistical association over symbolic data can often be sufficient. But when a model controls a robot, designs an experiment, recommends a treatment, or reasons about biological intervention, its outputs affect the system it observes. The model is no longer only predicting from a fixed distribution; it is participating in the process that generates future data.
The future of AI should therefore not be framed as scale versus causality. Scale provides capacity, coverage, and broad representations. Causality provides structure: variables, mechanisms, interventions, invariances, and counterfactuals. Without causal structure, larger models may become better at exploiting correlations that fail under shift. With causal structure, scaling can be directed toward extracting the right abstractions, discovering underlying mechanisms and hidden drivers, improving generalization under distribution shift, supporting reliable planning, and generating new knowledge.
The research programs developed by Pearl, Glymour, Schölkopf, Zhang, Huang, and others point toward a common conclusion: intelligence requires more than fitting observed distributions. It requires models that can represent how systems change, which mechanisms remain stable, and what would happen under alternative interventions.
Causality does not replace scaling. It gives scaling a more appropriate target for real-world intelligence: not only larger predictors, but models that recover variables, mechanisms, hidden drivers, and intervention-relevant structure from the world itself.
References
- Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press.
- Pearl, J. (2019). The seven tools of causal inference, with reflections on machine learning. Communications of the ACM, 62(3), 54–60.
- Pearl, J., & Mackenzie, D. (2018). The Book of Why: The New Science of Cause and Effect. Basic Books.
- Neyman, J. (1923/1990). On the application of probability theory to agricultural experiments: Essay on principles. Section 9. Statistical Science, 5(4), 465–472.
- Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66(5), 688–701.
- Spirtes, P., Glymour, C., & Scheines, R. (2000). Causation, Prediction, and Search (2nd ed.). MIT Press.
- Glymour, C., Zhang, K., & Spirtes, P. (2019). Review of causal discovery methods based on graphical models. Frontiers in Genetics, 10, 524.
- Chickering, D. M. (2002). Optimal structure identification with greedy search. Journal of Machine Learning Research, 3, 507–554.
- Shimizu, S., Hoyer, P. O., Hyvärinen, A., & Kerminen, A. (2006). A linear non-Gaussian acyclic model for causal discovery. Journal of Machine Learning Research, 7, 2003–2030.
- Hoyer, P. O., Janzing, D., Mooij, J. M., Peters, J., & Schölkopf, B. (2009). Nonlinear causal discovery with additive noise models. Advances in Neural Information Processing Systems.
- Zheng, X., Aragam, B., Ravikumar, P., & Xing, E. P. (2018). DAGs with NO TEARS: Continuous optimization for structure learning. Advances in Neural Information Processing Systems.
- Zhang, K., & Hyvärinen, A. (2009). On the identifiability of the post-nonlinear causal model. Proceedings of the Conference on Uncertainty in Artificial Intelligence.
- Zhang, K., Peters, J., Janzing, D., & Schölkopf, B. (2011). Kernel-based conditional independence test and application in causal discovery. Proceedings of the Conference on Uncertainty in Artificial Intelligence.
- Zhang, K., Zhang, J., Huang, B., Schölkopf, B., & Glymour, C. (2016). On the identifiability and estimation of functional causal models in the presence of outcome-dependent selection. Proceedings of the Conference on Uncertainty in Artificial Intelligence, 825–834.
- Huang, B., Zhang, K., Lin, Y., Schölkopf, B., & Glymour, C. (2018). Generalized score functions for causal discovery. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1551–1560.
- Huang, B., Zhang, K., Gong, M., & Glymour, C. (2019). Causal discovery and forecasting in nonstationary environments with state-space models. Proceedings of the International Conference on Machine Learning.
- Huang, B., Zhang, K., Xie, P., Gong, M., Xing, E. P., & Glymour, C. (2019). Specific and shared causal relation modeling and mechanism-based clustering. Advances in Neural Information Processing Systems.
- Huang, B., Zhang, K., Zhang, J., Ramsey, J., Sanchez-Romero, R., Glymour, C., & Schölkopf, B. (2020). Causal discovery from heterogeneous/nonstationary data. Journal of Machine Learning Research, 21(89), 1–53.
- Huang, B., Zhang, K., Gong, M., & Glymour, C. (2020). Causal discovery from multiple data sets with non-identical variable sets. Proceedings of the AAAI Conference on Artificial Intelligence.
- Zheng, Y., Huang, B., Chen, W., Ramsey, J., Gong, M., Cai, R., Shimizu, S., Spirtes, P., & Zhang, K. (2024). Causal-learn: Causal discovery in Python. Journal of Machine Learning Research, 25, 1–8.
- Xie, F., Huang, B., Chen, Z., Cai, R., Glymour, C., Geng, Z., & Zhang, K. (2024). Generalized independent noise condition for estimating causal structure with latent variables. Journal of Machine Learning Research, 25, 1–61.
- Dong, X., Huang, B., Ng, I., Song, X., Zheng, Y., Jin, S., Legaspi, R., Spirtes, P., & Zhang, K. (2024). A versatile causal discovery framework to allow causally-related hidden variables. International Conference on Learning Representations.
- Huang, B., Low, C., Feng, X., Glymour, C., & Zhang, K. (2022). Latent hierarchical causal structure discovery with rank constraints. Advances in Neural Information Processing Systems.
- Kong, L., Huang, B., Xie, F., Xing, E. P., Chi, Y., & Zhang, K. (2023). Identification of nonlinear latent hierarchical models. Advances in Neural Information Processing Systems.
- Liu, Y., Zhang, Z., Gong, D., Gong, M., Huang, B., van den Hengel, A., Zhang, K., & Shi, J. (2024). Identifiable latent polynomial causal models through the lens of change. International Conference on Learning Representations.
- Schölkopf, B., Janzing, D., Peters, J., Sgouritsa, E., Zhang, K., & Mooij, J. M. (2012). On causal and anticausal learning. Proceedings of the International Conference on Machine Learning.
- Peters, J., Bühlmann, P., & Meinshausen, N. (2016). Causal inference using invariant prediction: Identification and confidence intervals. Journal of the Royal Statistical Society: Series B, 78(5), 947–1012.
- Arjovsky, M., Bottou, L., Gulrajani, I., & Lopez-Paz, D. (2019). Invariant risk minimization. arXiv preprint arXiv:1907.02893.
- Schölkopf, B. (2019). Causality for machine learning. arXiv preprint arXiv:1911.10500.
- Schölkopf, B., Locatello, F., Bauer, S., Ke, N. R., Kalchbrenner, N., Goyal, A., & Bengio, Y. (2021). Toward causal representation learning. Proceedings of the IEEE, 109(5), 612–634.
- Zhang, K., Gong, M., Stojanov, P., Huang, B., Liu, Q., & Glymour, C. (2020). Domain adaptation as a problem of inference on graphical models. Advances in Neural Information Processing Systems.
- Lu, C., Huang, B., Wang, K., Zhang, K., Hernández-Lobato, J. M., & Schölkopf, B. (2020). Sample-efficient reinforcement learning via counterfactual-based data augmentation. NeurIPS Offline Reinforcement Learning Workshop.
- Huang, B., Lu, C., Liu, L., Hernández-Lobato, J. M., Glymour, C., Schölkopf, B., & Zhang, K. (2022). Action-sufficient state representation learning for control with structural constraints. Proceedings of the International Conference on Machine Learning.
- Huang, B., Feng, F., Lu, C., Magliacane, S., & Zhang, K. (2022). AdaRL: What, where, and how to adapt in transfer reinforcement learning. International Conference on Learning Representations.
- Feng, F., Huang, B., Zhang, K., & Magliacane, S. (2022). Factored adaptation for non-stationary reinforcement learning. Advances in Neural Information Processing Systems.
- Liu, Y., Huang, B., Zhu, Z., Tian, H., Gong, M., Yu, Y., & Zhang, K. (2023). Learning world models with identifiable factorization. Advances in Neural Information Processing Systems.
- Wang, X., & Huang, B. (2025). Modeling unseen environments with language-guided composable causal components in reinforcement learning. International Conference on Learning Representations.
- Yang, Y., Huang, B., Feng, F., Wang, X., Tu, S., & Xu, L. (2025). Towards generalizable reinforcement learning via causality-guided self-adaptive representations. International Conference on Learning Representations.
- Wang, X., Zhou, K., Wu, W., et al., & Huang, B. (2025). Causal-Copilot: An autonomous causal analysis agent. arXiv preprint arXiv:2504.13263.