When AI Starts Acting, Prediction Is Not Enough
AI systems are beginning to move from answering questions to taking actions. They call tools, control workflows, suggest policies, and increasingly operate inside scientific and robotic systems.
But action is not just prediction. Before an AI system changes a lab protocol, recommends an intervention, or controls a robot, it needs to answer a harder question: what would my action actually change?
This is where causality matters. A predictive model can tell us what is likely to happen next. A causal system helps us reason about why something happens, what would happen under a different intervention, and which assumptions make the answer valid.
Causal Copilot is our early, runnable expression of this direction: an agentic system for recovering causal structure, estimating effects, reasoning about alternatives, and translating causal evidence into better decisions.
A Lab Looking for Mechanisms
Imagine an automated materials lab running hundreds of synthesis experiments each week. Each run records precursor ratios, solvents, humidity, temperature schedules, stirring speed, cooling conditions, intermediate measurements, yield, and long-term stability.
A predictive model can rank which future runs look promising. It may learn that certain parameter combinations often appear in successful batches. That is useful, but it does not answer the scientific question.
The scientist wants to recover the mechanism. Does humidity directly affect stability, or does it change an intermediate phase? Does the temperature ramp rate matter because of thermal history, or because certain instruments were used during a particular batch period? If precursor ratio appears predictive, is it a real lever or a proxy for something else?
The point of the example is not the particular domain. It is the shape of the question Causal Copilot is built to support: turning observations into candidate mechanisms, and candidate mechanisms into better next steps.
The same pattern appears in biology, clinical decision-making, policy, product analytics, robotics, and embodied AI. The central question is not only what correlates with success, but what produced the outcome and what intervention would reduce uncertainty.

Causal Copilot
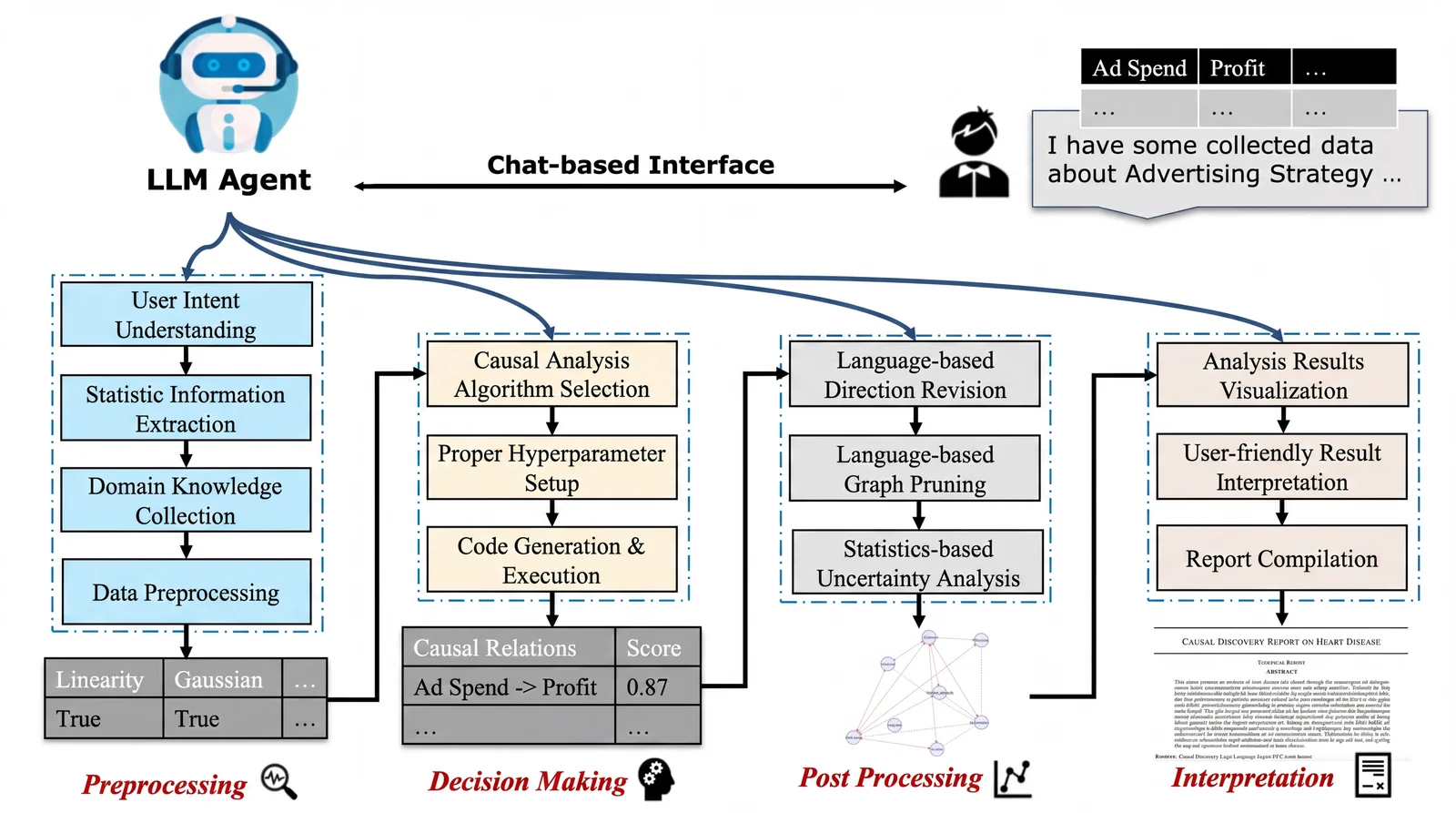
Causal Copilot is an autonomous causal analysis agent that carries a causal question from formulation and assumption management through discovery, identification, estimation, counterfactual reasoning, robustness checking, and explanation.
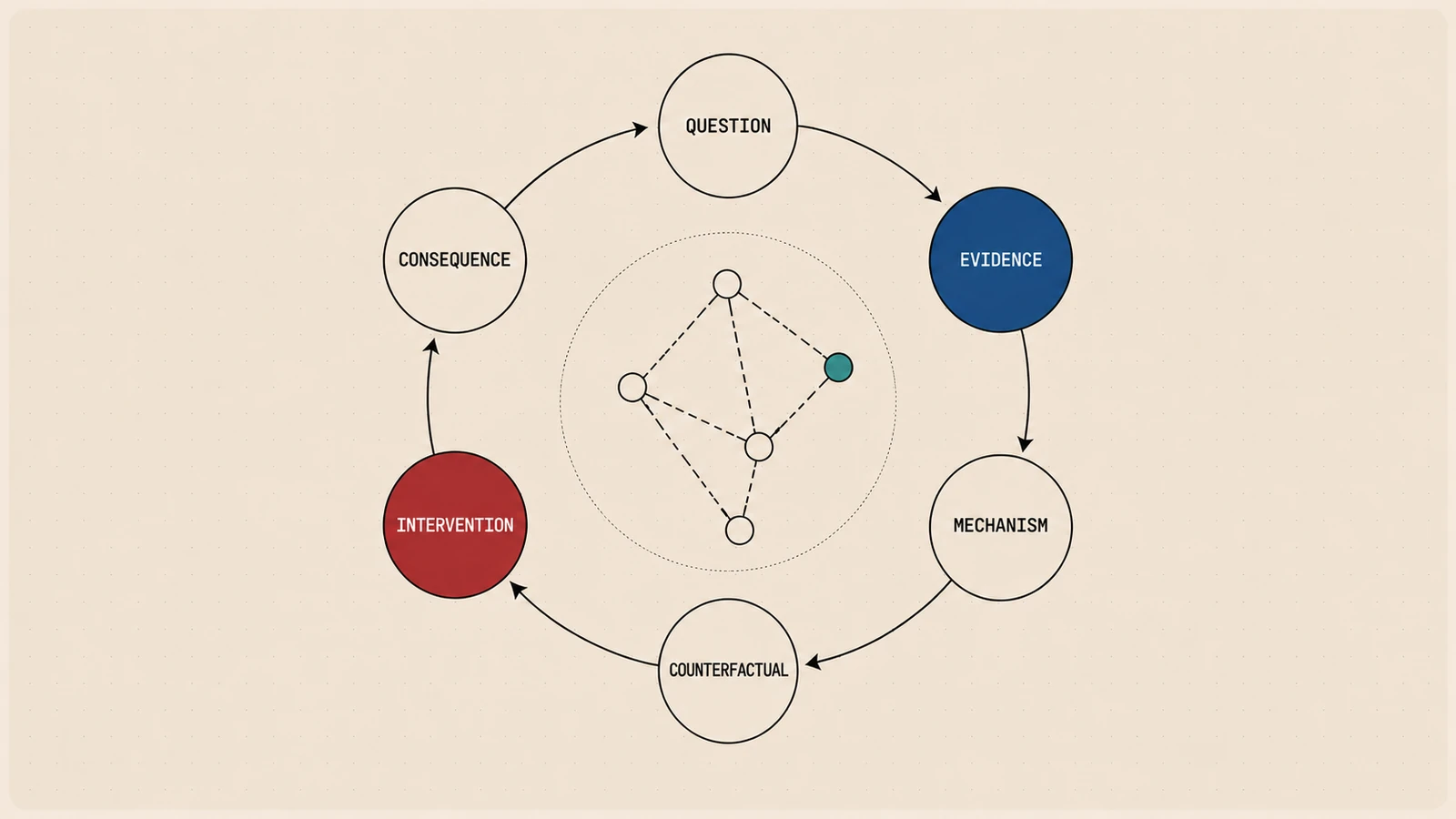
The Reasoning Loop Inside Causal Copilot
Causal analysis is not one algorithm. It is a reasoning loop over questions, assumptions, mechanisms, effects, counterfactuals, and robustness. Causal Copilot makes that loop executable.
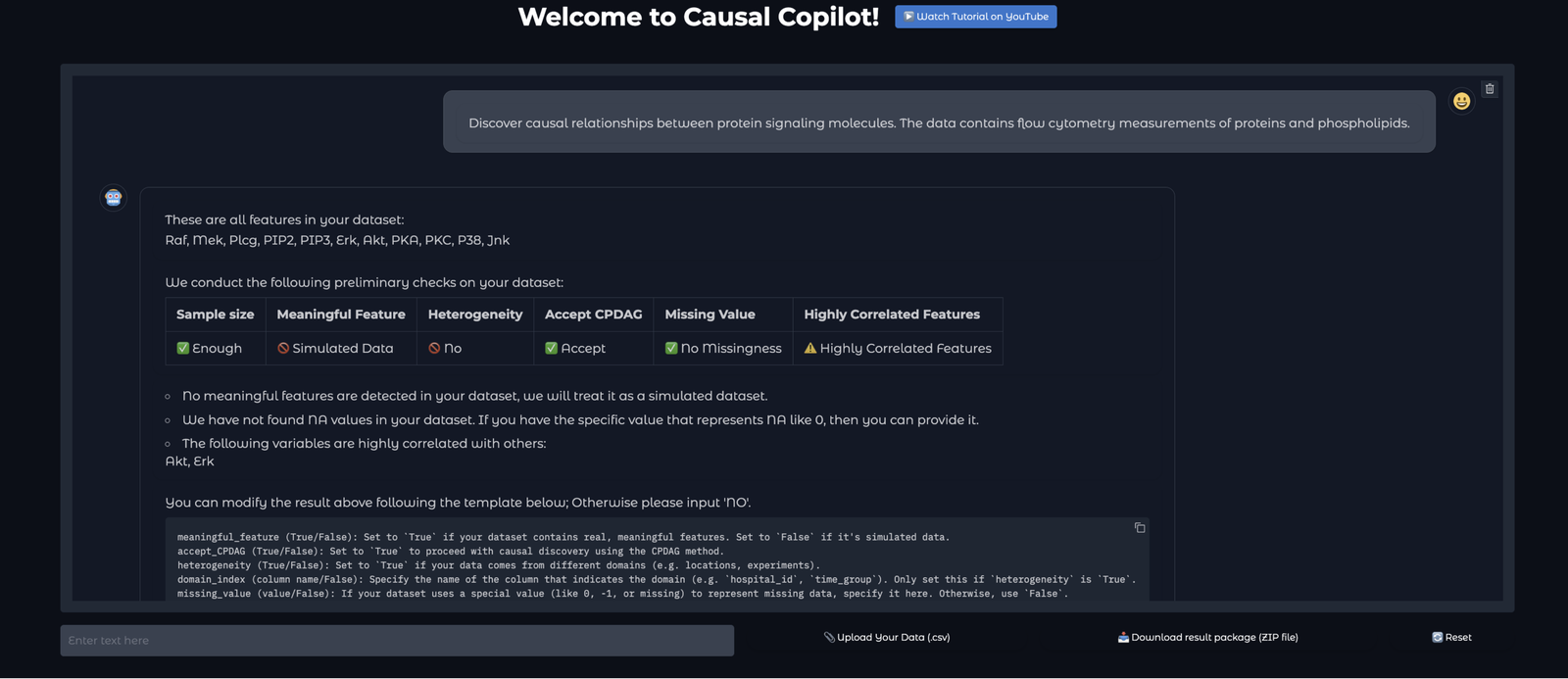
Making the Question Causal
Causal analysis begins before any algorithm runs. A user may ask whether a strategy works, why an outcome changed, which factor drives a failure, or what experiment to run next. The agent must translate that intent into treatment, outcome, unit of analysis, time window, candidate covariates, and estimand.
If the outcome is defined incorrectly, if temporal order is ignored, or if the analysis adjusts for variables that occur after treatment, the downstream estimate can become misleading. Causal Copilot makes this setup explicit before the analysis begins.
Reading the Data Before Choosing the Tool
Before choosing a causal method, Causal Copilot builds a statistical profile of the dataset. For tabular data, it checks variable types, missingness, distributional shape, linearity, heterogeneity, and data quality. For time-series data, it checks stationarity, lag structure, and temporal dependencies.
These diagnostics determine which causal assumptions are plausible and which algorithms are compatible with the data. The system then narrows the method space using user constraints, causal expert knowledge, and runtime considerations.
Discovering Candidate Mechanisms
Causal discovery proposes a mechanism map: which variables may influence which others, which paths appear stable, and which relationships deserve further testing.
Discovery does not replace scientific judgment, and it does not turn observational data into certainty. Its value is that it makes possible mechanisms visible, inspectable, and connected to downstream identification and estimation.
Causal Copilot supports discovery across tabular and time-series settings and can draw on multiple method families, including constraint-based, score-based, continuous-optimization, LiNGAM-style, Markov-blanket, Granger-style, and time-series causal discovery methods.
The discovered graph is treated as a hypothesis to refine, not a finished answer. Causal Copilot estimates edge confidence through bootstrap-style resampling, flags uncertain relationships, removes weak edges, and uses the language model as a structured plausibility checker for moderate-confidence cases. Human feedback can trigger re-analysis where needed.
Identifying and Estimating Effects
Once a candidate structure is available, the next question becomes sharper: under what assumptions can we estimate the effect of changing one variable on another?
This is where identification matters. The agent must reason about adjustment sets, confounders, mediators, colliders, instruments, front-door and back-door paths, temporal order, and the data regime.
Causal Copilot can connect the identified question to suitable estimators such as matching, adjustment-based methods, instrumental-variable approaches, doubly robust methods, and other causal inference tools. The important capability is not tool breadth alone. It is the ability to keep the estimand, assumptions, data, and method choice aligned.
A reliable causal agent should sometimes say that a query cannot be answered from the available data and assumptions. That refusal is part of methodological rigor.
Asking Counterfactual Questions
Counterfactual questions ask what would have happened under a different condition. In a lab, this might mean asking whether a failed run would have succeeded if humidity had been held fixed. In robotics, it might mean asking whether the object would still have slipped if the gripper contact point or force profile had changed.
Counterfactual reasoning compares an observed world with an alternative world under a causal model and stated assumptions. That is what makes it useful for policy, experiment design, and embodied action.
Challenging the Result Before It Becomes a Claim
A causal result should be challenged before it becomes a claim. Causal Copilot can run checks such as sensitivity analysis, placebo-style tests, alternative specifications, uncertainty assessment, graph confidence checks, and comparisons across plausible method choices.
The final explanation should say what the answer depends on, which relationships remain uncertain, and what would make the answer fail.

What the System Covers
Breadth matters because causal questions are heterogeneous. A tabular treatment-effect question, a temporal mechanism question, a counterfactual policy question, and an abnormality-attribution question do not ask for the same tool.
Causal Copilot therefore integrates more than 20 causal analysis techniques across causal discovery, causal effect estimation, counterfactual reasoning, and auxiliary analyses. The goal is not to suggest that one method fits all problems. It reflects the opposite: causal analysis is assumption-sensitive, data-regime-sensitive, and task-sensitive, so a useful causal agent needs a broad but disciplined toolbox.
In the implemented workflow, discovery is not the terminal output. Causal Copilot can use the discovered or refined structure for downstream analyses such as causal effect estimation, counterfactual estimation, feature importance, and causal-structure-based abnormality attribution.
From a Causal Question to an Inspectable Report
A typical user does not begin with an algorithm. They begin with a causal question: what drives this outcome, what would happen if we changed this variable, or which mechanism explains this failure?
Causal Copilot turns that question into an explicit analysis target, profiles the data, selects compatible methods, proposes a candidate graph, asks which effects are identifiable, estimates effects when possible, and challenges the result through robustness checks and graph refinement.
The useful output is not only a number or a graph. It is an inspectable analysis record: what question was asked, what diagnostics were observed, why a method was selected, which relationships were uncertain, what the estimated effect depends on, and what further evidence would make the conclusion stronger.

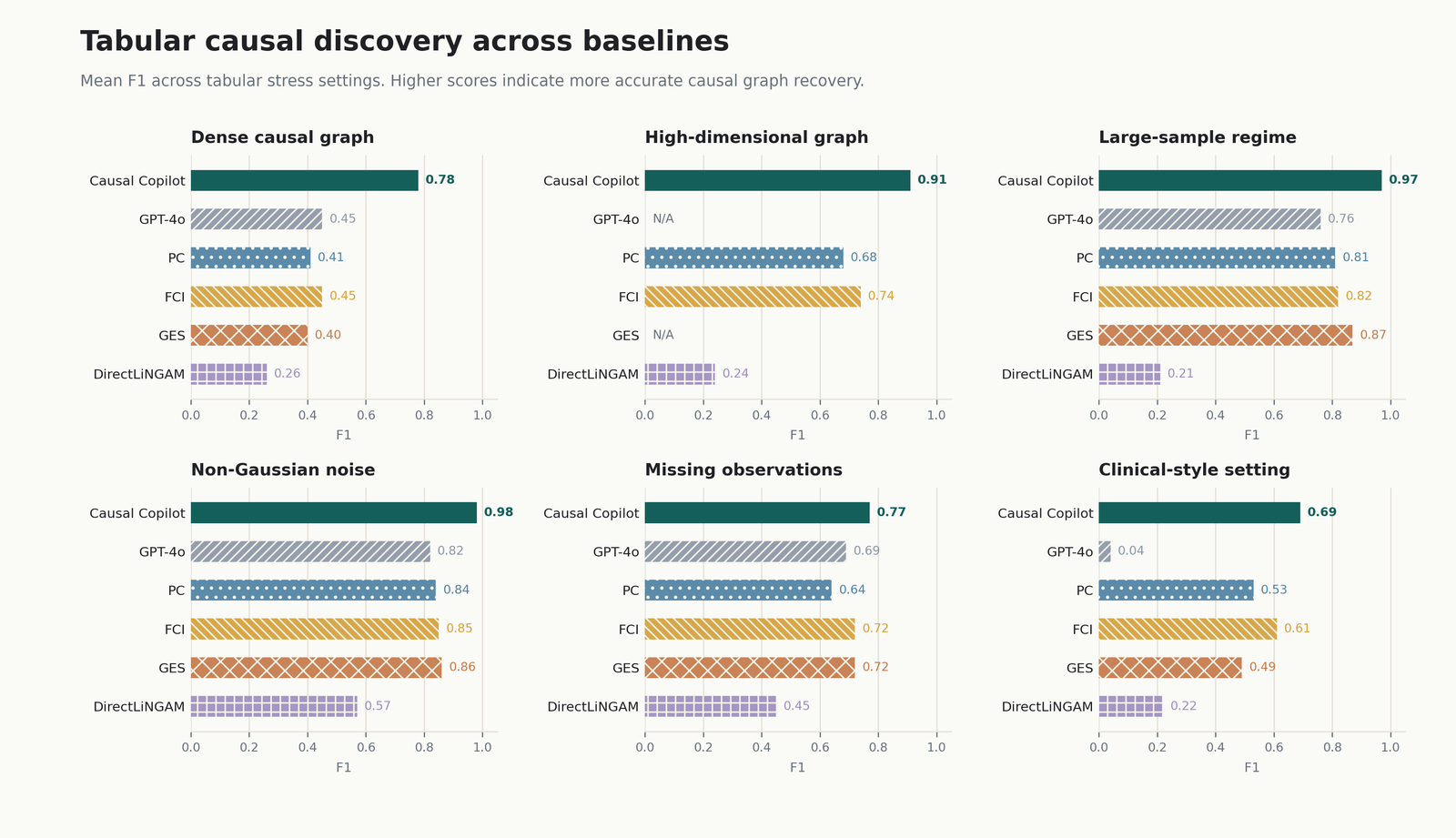
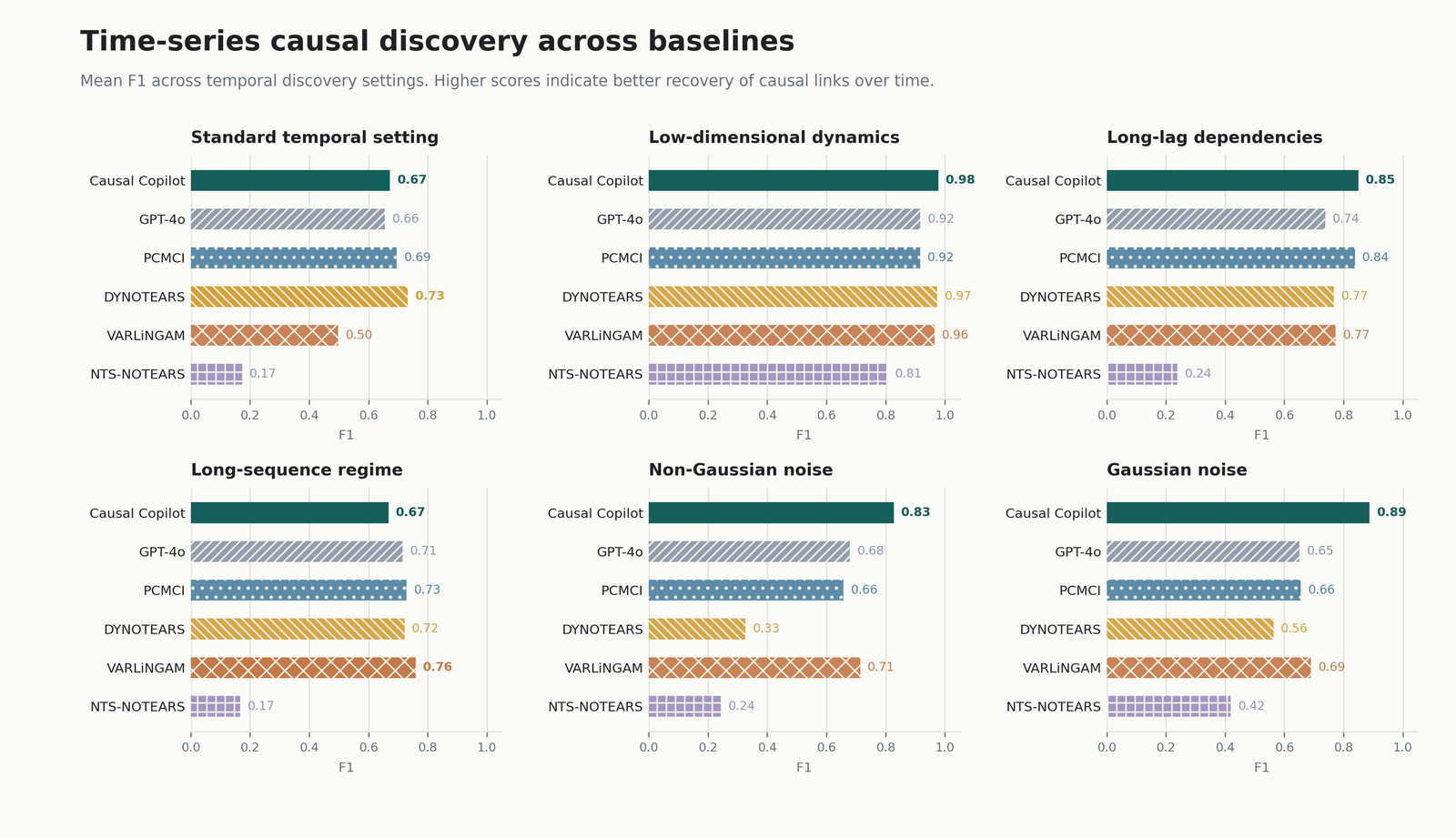
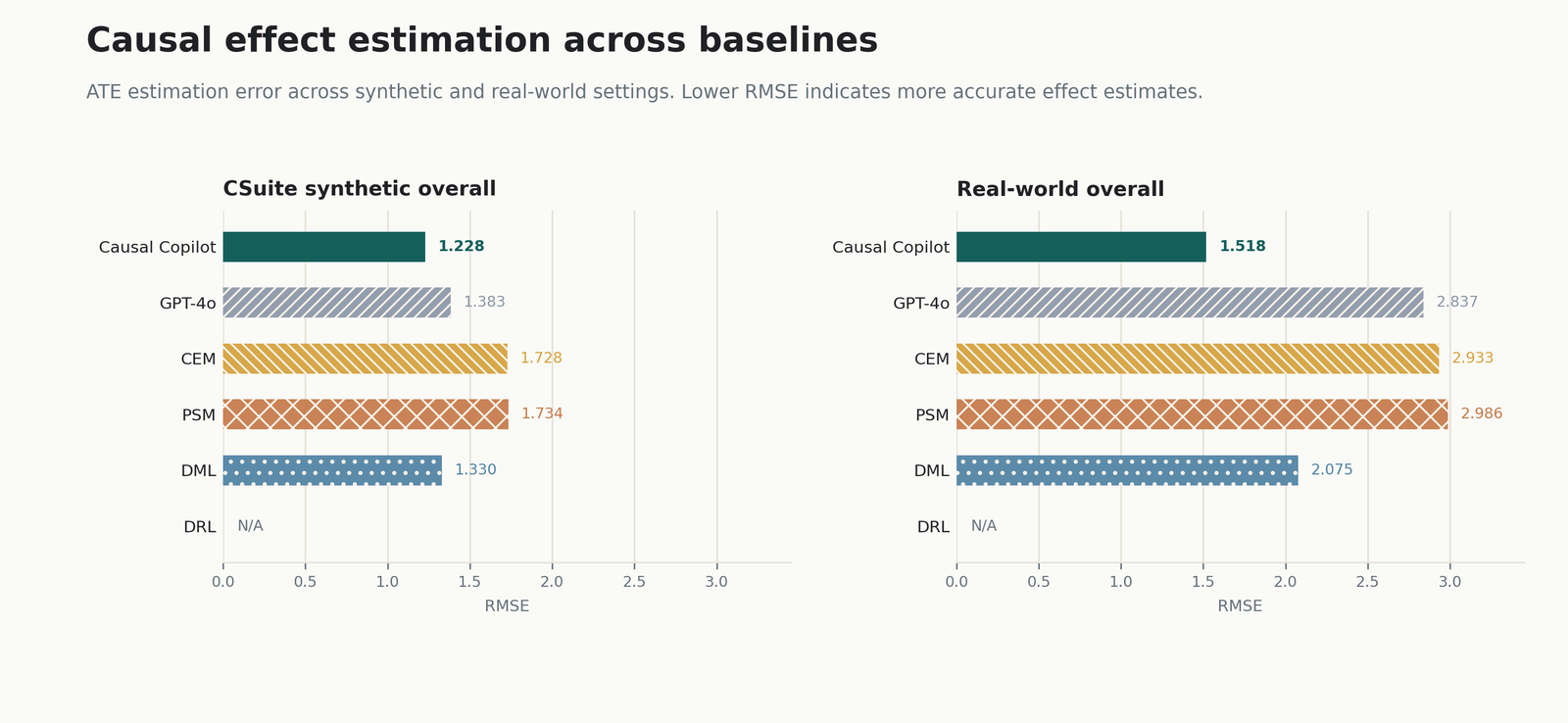
Evaluation Across Data Regimes
We evaluated Causal Copilot across controlled tabular and time-series settings rather than only showing a demo. For tabular data, the tests vary dimensionality, graph density, sample size, relationship type, noise, discreteness, measurement error, and missingness. For time-series data, they vary dimensionality, sample size, lag structure, temporal density, and noise. The evaluation also includes synthetic compound scenarios inspired by clinical, financial, social-network, and sensor-system scenarios.
Causal Copilot is evaluated against individual causal discovery methods and a non-contextualized GPT-4o baseline. The GPT-4o baseline receives the same user query and candidate method space, but does not have the same statistical diagnostics and causal expert knowledge.
The point is not to claim a universal best method. It is to make algorithm selection empirical: different causal questions require different tools, and the system should learn when each tool is appropriate.
Toward AI That Understands Consequences
Causal Copilot is not the final form of causal AI. It is an early concrete expression of our broader causality-centric AI vision: systems that discover structure before acting, expose the assumptions behind their conclusions, and reason about what their actions would change.
For science, that means moving from observations to candidate mechanisms, from mechanisms to identifiable questions, and from those questions to experiments that improve the model. For robotics, it means treating action as an intervention: before committing, the system should ask what the action would change, which variables mediate success or failure, what transfers from prior settings, and which uncertainties remain. For decision-making, it means replacing correlation-driven recommendations with claims that can be inspected.
To discover is to make the world legible. To act is to test that understanding. Causal Copilot connects these two halves of intelligence into one agentic loop.
To see the loop in motion, explore the code and try the live demo.
References
- Wang, X., Zhou, K., Wu, W., et al., & Huang, B. (2025). Causal-Copilot: An autonomous causal analysis agent. arXiv preprint arXiv:2504.13263.