World models are often described as predictive models. Given the past observations and actions of an agent, they learn to predict what will happen next. In embodied systems, a world model can be naturally used for policy evaluation and improvement: if an agent can imagine future observations under different actions, it should be able to use the future judgment to plan better.
A standard world model can be written as
or, after encoding observations into a latent state,
Modern world models can predict future frames, learn compact latent dynamics, support MBRL or policy improvement for VLAs, and even generate visually realistic future videos. However, prediction alone is not the same as understanding. A model may predict well on the training distribution while still failing to know which factors are controllable, which correlations are spurious, which mechanisms are reusable, and whether an imagined long-horizon plan is physically reachable.
This gap becomes more serious in embodied settings. A robot operating in the real world must generalize across new objects, layouts, embodiments, and tasks. It must reason over long horizons, compose known mechanisms in unseen ways, and decide when to actively collect new data. In such settings, a world model should not merely imitate observed trajectories. It should discover the causal structure of the environment.
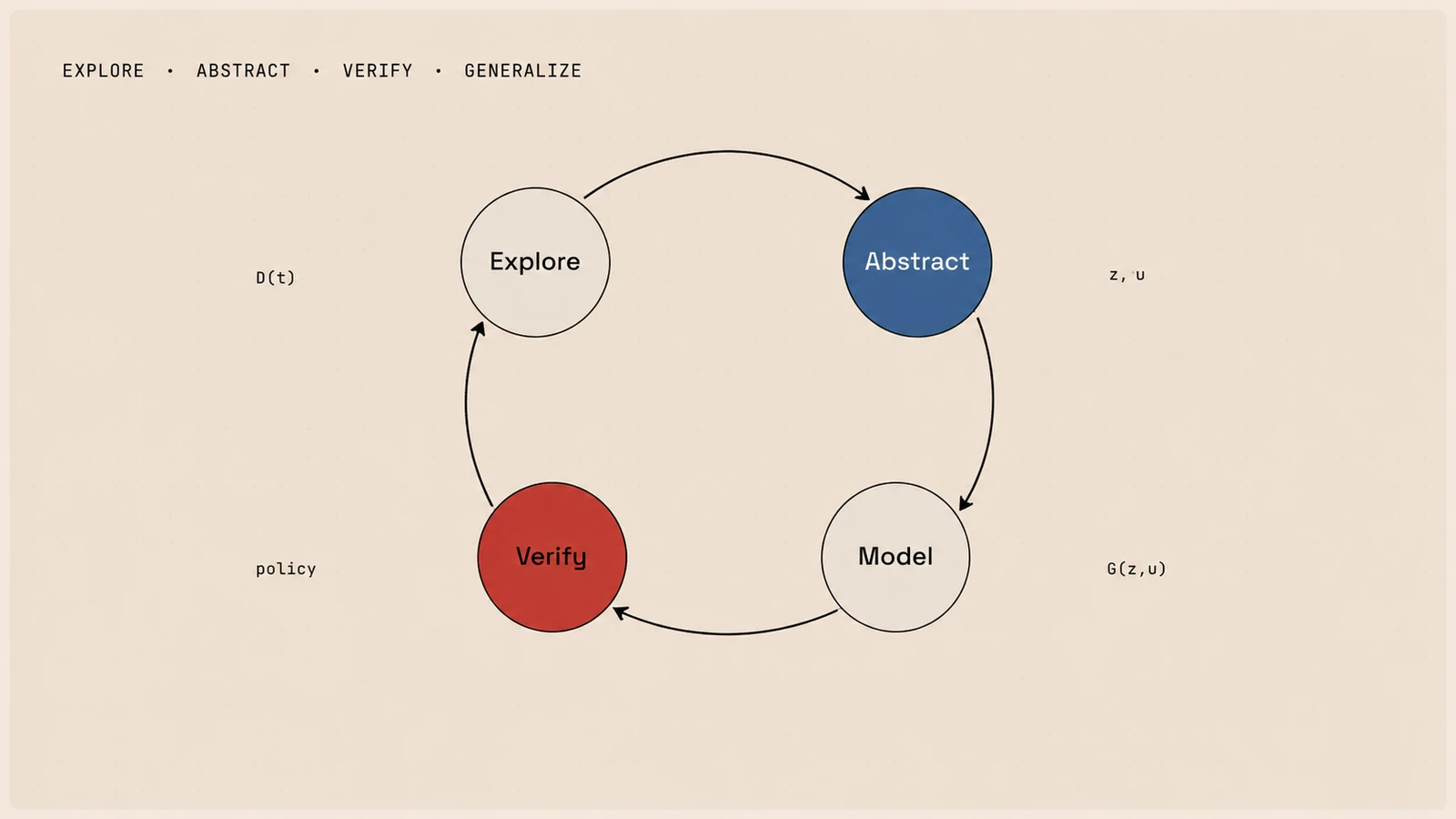
In this blog, we describe a recipe for learning causal world models. Crucially, a causal world model should learn a shared causal structure of states, actions, and mechanisms, and use this structure to guide exploration, representation learning, and decision making in a closed loop.
Explore -> abstract states and actions -> learn causal structure -> plan, verify, and generalize -> explore again.
Why Predictive World Models Are Not Enough
The usual objective of a world model is to predict the future. In pixel space, this means predicting future observations. In latent space, this means predicting future latent states. Both are useful, but both can hide an important problem: the model may learn correlations that are sufficient for short-term prediction but insufficient for robust decision making.
For example, suppose a robot always sees a red cube on a wooden table during training. A predictive model may entangle the cube state, texture, lighting, and camera viewpoint into a single latent representation. This may be acceptable for reconstruction or short-horizon prediction, but it is fragile for control. If the table texture changes, the model may drift. If the cube is replaced by a blue object, the policy may fail. If a new task requires pushing the object before grasping it, the model may not know how to compose the relevant mechanisms.
Thus, a causal world model should answer questions that go beyond next-step prediction:
- What aspects of the world matter for control?
- What can the agent change through intervention?
- Which mechanisms are invariant across contexts?
- Which action effects can be shared across embodiments?
- Which imagined futures are physically plausible and action-reachable?
A predictive world model learns what tends to happen. A causal world model should learn why it happens, what would happen under alternative interventions, and how these mechanisms can be reused.
2. A Closed-Loop Recipe for Causal World Models
A useful way to think about a causal world model is not as a single predictor, but as a loop between the agent and the model. The agent collects experience, the model turns that experience into a compact understanding of the world, and this understanding then changes what the agent explores next.
In a recent framework, we study how agentic exploration and structured world-model learning can co-evolve. The key message is that the agent should not collect data blindly, and the model should not represent everything it sees. Instead, the agent should actively probe the environment to expose task-relevant factors, while the model should distill those interactions into a causal representation for decision making.
Agent explores -> model learns what matters -> policy improves -> agent explores better.
The first step is exploration. But exploration here does not only mean visiting more states or maximizing visual novelty. It means asking the environment useful questions. For example, an agent may push, lift, rotate, or perturb objects to discover which factors affect the task. These interactions reveal information that passive data may never contain.
The second step is structured modeling. Once the agent has collected informative trajectories, the world model should not simply compress all observations into a large latent vector. It should identify the subset of factors that are actually needed for control.
The third step is decision making. A policy trained on a compact, task-sufficient representation is less distracted by irrelevant variation. It can reuse the same useful factors across related tasks, compose them in new ways, and adapt more efficiently when the environment changes.
Finally, we close the loop. A better model can reveal what the agent still does not understand, for example uncertainty about contact or how mass changes object motion. These gaps tell the agent where to probe next.
This closed-loop view is important because causal structure rarely appears from passive observation alone. The agent often needs to act in order to discover what matters. At the same time, action is only useful when the model knows how to turn experience into reusable structure. Causal world-model learning therefore requires both sides: exploration that reveals the right factors, and modeling that keeps only the factors needed for control.
Hence, a causal world model is not merely a better latent predictor. It is a learning loop that decides what data to collect, what state and action abstractions to keep, and how those abstractions should support robust decision making.
3. Causality-Guided Exploration: Data as Intervention
The first ingredient is exploration. For a causal world model, exploration is not just about visiting many states or maximizing novelty. It is about collecting interactions that reveal how the world changes under interventions.
A simple way to state the goal is:
Here, \(\tau\) is an interaction trajectory. The goal is to collect trajectories that are informative about the factors that matter for control, such as object position, contact, mass, affordance, relation, or task-relevant context.
The agent uses probing behaviors to actively perturb the environment: push an object, lift it, rotate it, touch it, fail to grasp it, or try the same action under different configurations. These interactions help reveal which latent factors affect observations, rewards, and future states.
For example, observing a cube on a table may not reveal whether its mass matters. But trying to lift two cubes with different weights may expose a factor that is invisible from appearance alone. Similarly, seeing a closed drawer is less informative than attempting to open it and observing which state variables change.
In this sense, exploration should be guided by causal contrast:
If two interventions from a similar state lead to different outcomes, the difference helps identify the causal effect of the action. If the same intervention behaves differently in two contexts, the contrast helps identify the relevant state or context factor.
In essence, the best data for a causal world model is not necessarily the most visually diverse data. It is the data that makes the causal structure of the environment easiest to discover.
4. Unified Latent Action: Modeling What the Agent Does
After exploration, the next question is how the model should represent action. In embodied world models, action should not be treated as a raw command attached to a particular robot. A joint command, a gripper command, a mobile-base command, or a human hand motion may look very different, but they can produce similar changes in the world.
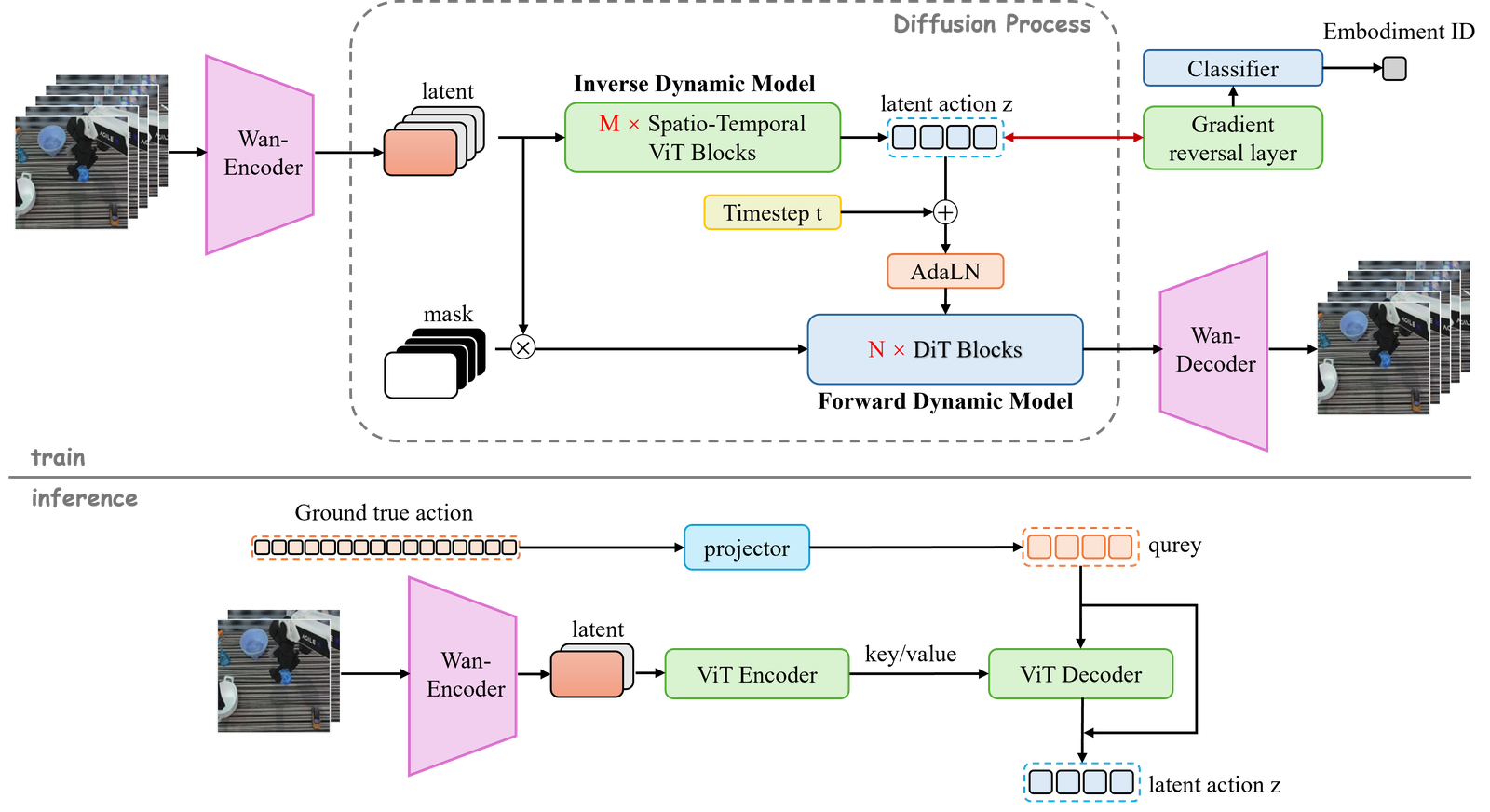
This motivates a unified latent action: an action representation that captures the controllable change in a transition, rather than the embodiment-specific command used to produce it.
A simple formulation is:
or, when raw actions are available,
Here, \(u_t\) is not meant to be a motor command. It is a learned representation of the intervention: what changed, which object moved, which relation was created or removed, whether contact happened, and how the action affected the scene. Instead of conditioning the world model directly on embodiment-specific raw actions, we learn latent actions from visual transitions using an inverse-forward dynamics view. The inverse model infers the latent action from a transition, and the forward model checks whether that latent action is sufficient to predict what happens next.
The resulting world model can be written as:
For cross-embodiment settings, each body may have its own way of realizing the same latent action:
This separation is important. The embodiment-specific part explains how a particular body executes an intervention. The shared latent action explains the effect of that intervention on the world. In this view, cross-embodiment transfer is not about forcing different robots to share the same command space. It is about making them share the same causal action language.
This also clarifies what a good action abstraction should avoid. If the latent action simply memorizes future pixels, it becomes a visual shortcut. If it encodes robot identity, camera style, or embodiment-specific appearance, it will not transfer. A useful latent action should be predictive enough to explain the transition, compact enough to avoid hiding irrelevant details, and invariant enough to suppress embodiment-specific nuisance factors.
The broader message is that a causal world model should abstract both state and action. State tells us what matters in the world. Latent action tells us what intervention is applied to the world. Together, they provide a cleaner interface for learning reusable dynamics.
5. Causal Verifier: Verifying Generated Futures
The second model-level ingredient is verification. Modern video generative models are powerful because they can synthesize diverse and visually realistic futures. This makes them attractive as world action models: given a current observation and a task, they can imagine possible future trajectories and sometimes decode actions from them.
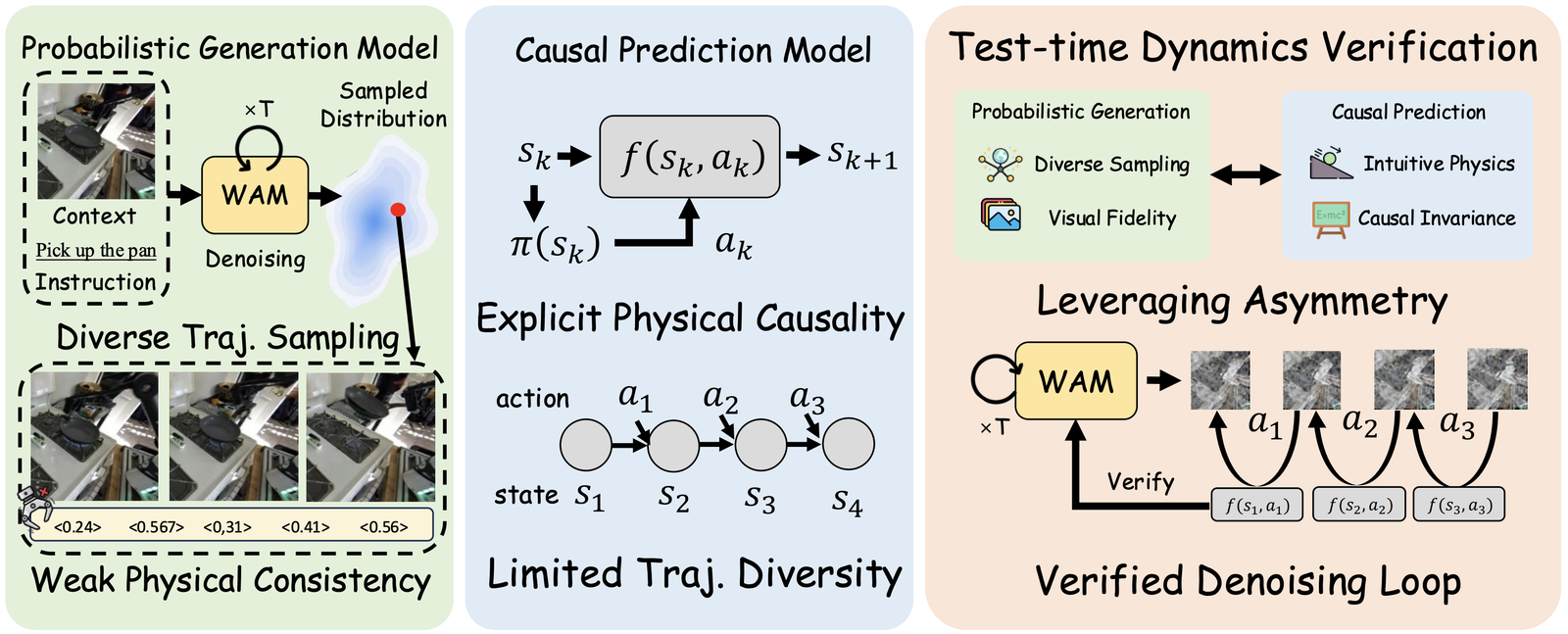
However, visual realism is not the same as physical validity. A generated video may look plausible frame by frame while still violating causal dynamics. Objects may move before contact, robot arms may blur into impossible shapes, or an interaction may appear without a physically reachable action. This is especially problematic in contact-rich manipulation, where small physical errors can corrupt the action signal.
This suggests a useful way for improving world models: generative model proposes futures; causal verifier checks dynamics.
The generative model is good at visual diversity and high-fidelity synthesis. The predictive world model is better at enforcing local causal transitions. Rather than forcing one model to do both perfectly, we can decouple generation and verification.
A simple verifier can be written as a dynamics consistency loss:
Here, \(h_t\) is a predictive feature of the generated state, \(a_t\) is the action or action-like variable, and \(f\) is a learned predictive dynamics model. If the generated transition agrees with the verifier, the energy is low. If the generated future violates the learned dynamics, the energy becomes high.
Hence, instead of retraining a large video generation backbone, a causal model can be used at inference time to steer the generated trajectory toward physically plausible states. The verifier does not need to generate beautiful videos by itself. It only needs to detect whether the proposed transition is dynamically consistent.
This gives a natural causal role to causal world models in the era of video generation. They can act as critics of generated futures. They can reject or correct hallucinated interactions. They can provide gradients or scores that guide sampling toward action-reachable trajectories.
Conceptually, this turns a world model into more than a simulator. It becomes a verifier of imagination. The generative model asks, "What futures might look plausible?" The causal verifier asks, "Which of these futures could actually happen under the intended action?"
This is especially important for long-horizon reasoning. Over many steps, small physical errors compound. A causal verifier can anchor generation to the dynamics manifold, reducing drift while preserving the diversity and visual richness of the generative model.
Together with unified latent actions, this gives a model-level recipe for causal world models: use latent actions to represent controllable interventions, and use causal verification to ensure that imagined futures remain physically and action-consistent.
6. From Better Imagination to Better Control
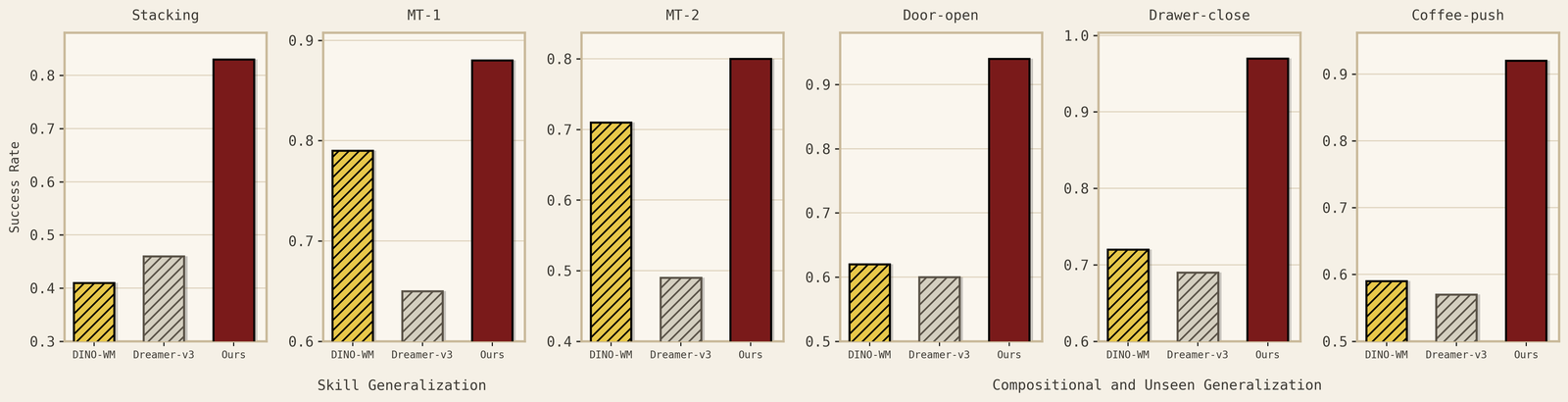
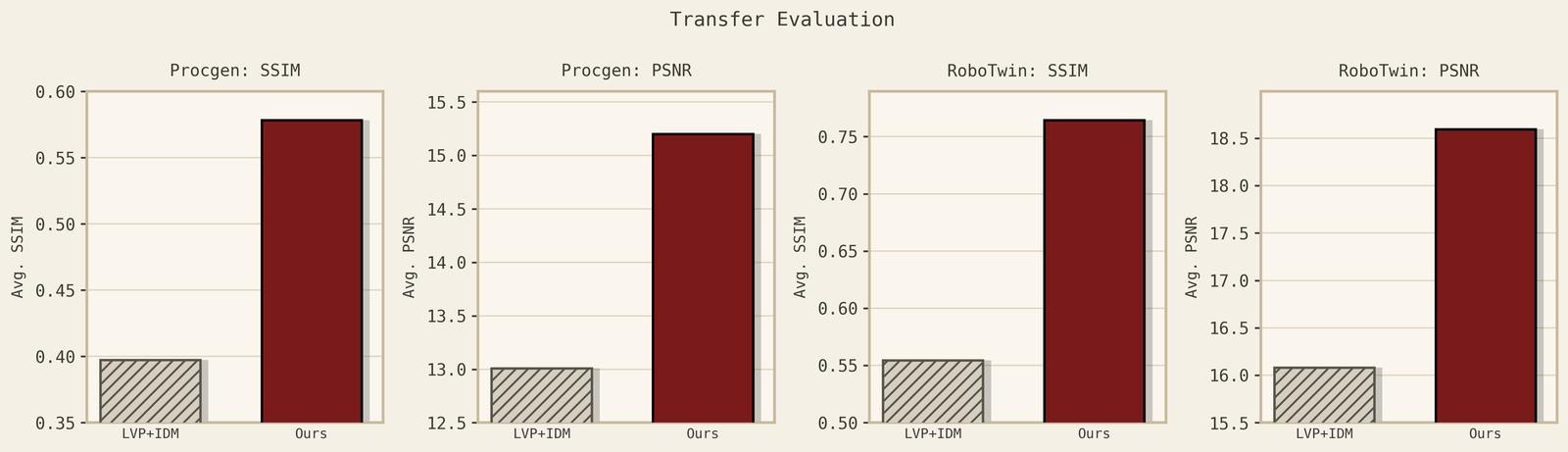
The previous sections describe the recipe. The main empirical question is whether causal structure improves both imagination and control. At the world-model level, success should mean more than sharper videos or lower prediction error: the model should predict the right physical consequences of interventions, especially in contact-rich scenes where objects move only after contact, grasps respect support, and generated rollouts preserve the target embodiment rather than hallucinating the source robot. At the decision level, these better imagined futures should translate into higher long-horizon success, including tasks that chain reaching, grasping, lifting, placing, stacking, or opening, as well as generalization to new task compositions and new embodiments that realize the same intervention through different motor commands.
Contact-rich world-model behavior. A causal world model should predict the physical consequences of interaction, not just generate sharp frames. In contact-rich scenes, objects should move after contact, grasps should respect support, and generated rollouts should avoid physically impossible transitions. And importantly, the improvement in world models can be translated into policy improvement.
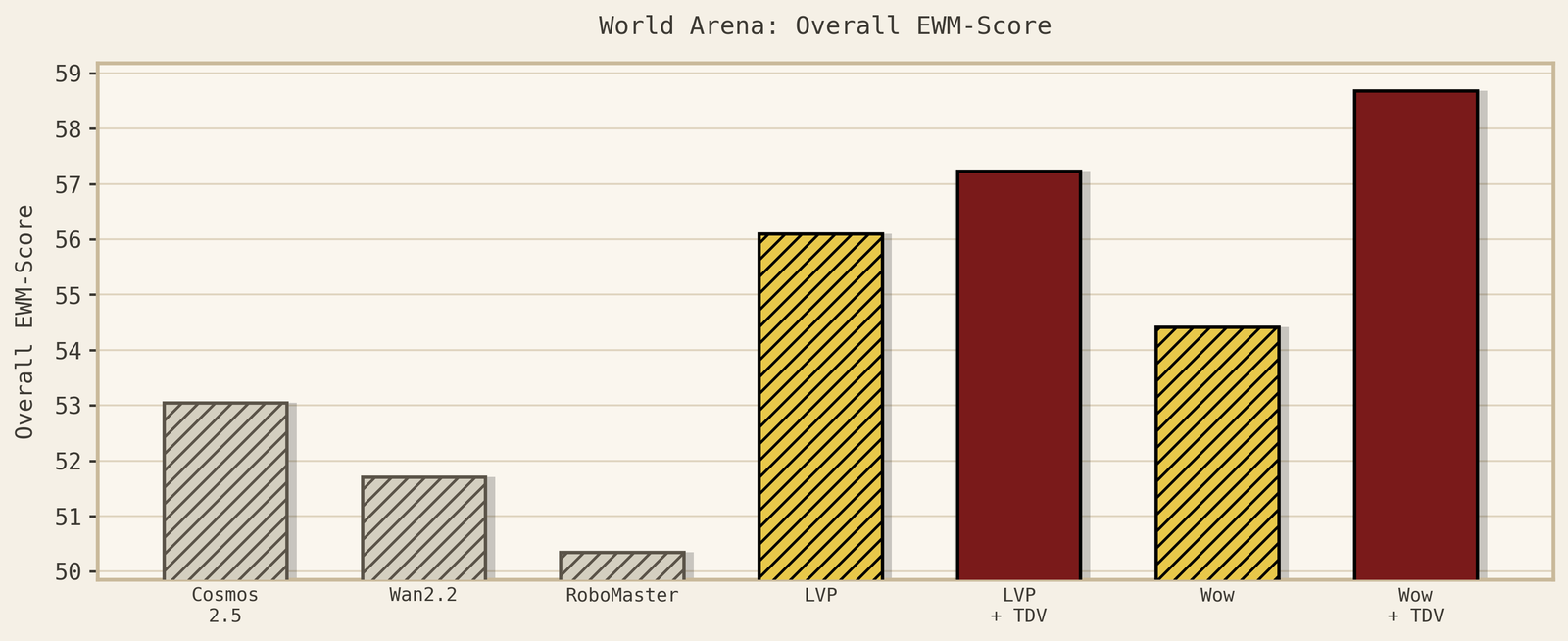
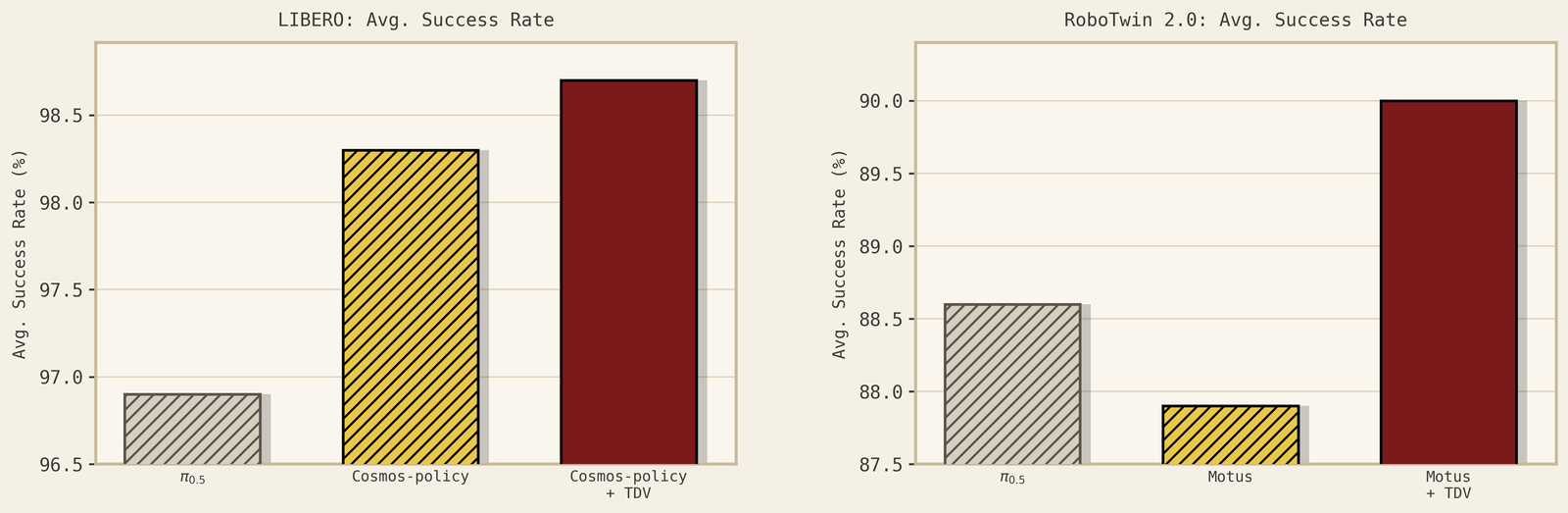
Long-horizon planning. Better imagined futures should translate into better decisions. This is tested by tasks that require chaining multiple steps, such as reaching, grasping, lifting, placing, stacking, opening, or inserting. Below, we show how we transfer from Aloha robots to Franka with zero samples.
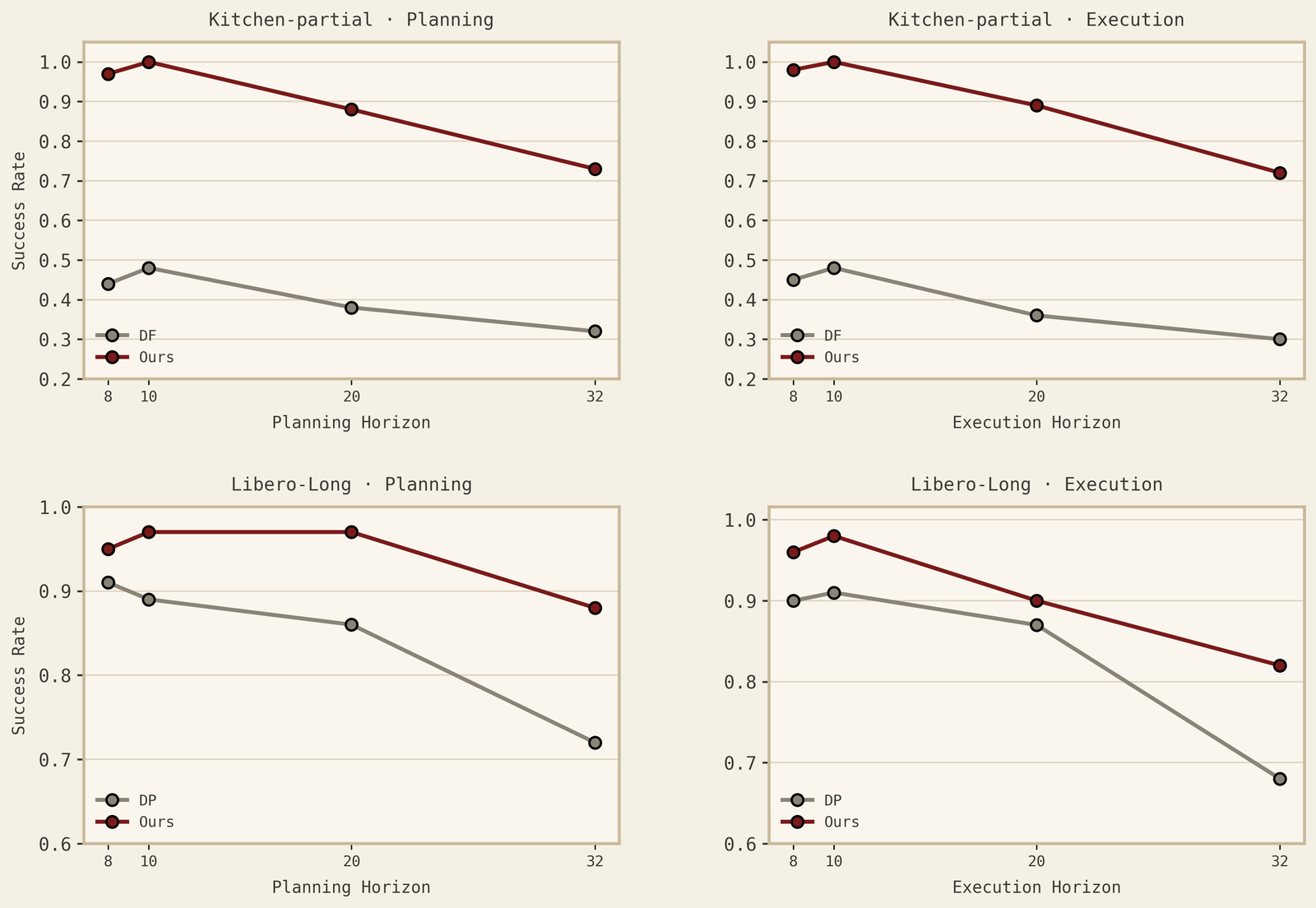
Compositional and cross-embodiment generalization. A causal world model should reuse learned mechanisms in new task compositions and across new bodies. The key test is whether the same intervention-level structure transfers across embodiments without copying the source robot’s morphology or action interface.